
Pandas의 데이터 유형에는 1차원 데이터인 Series와 2차원 데이터인 DataFrame이 있습니다.
이번 포스팅에서는 Series를 만드는 방법에 대해서 알아 보겠습니다.
class pandas.Series(data = None, index = None, dtype = None, name = None, copy = False, fastpath = False)
Parameter
data : array-like, iterable, dict, scalar value
index : array-like or index, 단, data의 개수와 같아야 합니다. index를 지정해주지 않는다면 0~n까지의 값이 순서대로 부여 됩니다.
dtype : str, numpy.dtype, ExtensionDtype, optional
name : str, optional
copy : True or False, Series를 생성하기 위해 사용된 input data에 영향을 주는지 여부를 나타냅니다. False로 설정하면, Series를 변경시킬 경우 input data에 영향을 줍니다.
1) data
dictionary와 list를 사용하여 Series를 생성한 결과입니다.

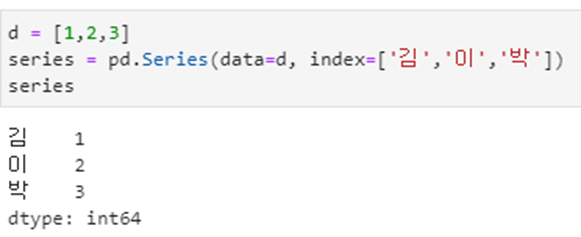
2) index
dictionary와 list를 사용하여 만들어진 데이터를 이용하여 Series를 생성하였습니다.
dictionary의 경우 Key값이 Index로 사용되는데요. index를 따로 지정해 줄경우 값과의 매칭을 모두 잃어 버리고 새로 생성된 Series의 index의 매칭 값들은 NaN이 되는 것을 확인할 수 있습니다.
이런 경우 index 옵션을 안주고 생성 한뒤 series.index를 사용해서 직접 입력해주면 변경됩니다.

3) dtype
Series를 생성할 때 데이터 타입을 결정해 줄 수 있습니다. 아무것도 입력하지 않는다면 Series 생성 시 데이터를 확인하고 자동으로 타입을 정해줍니다.

4) name
Series의 이름을 지정해 줄 수 있습니다.

5) copy
Series를 만들때 원본을 카피해서 사용할지 아니면 원본 그대로를 사용할 지 결정합니다.
False일 경우 원본을 카피하지 않고 그대로 쓰기 때문에 Series의 0번째 값을 1에서 123으로 변경하는 경우 원본 또한 123으로 변경된 것을 볼 수 있습니다.

Copy의 경우 ndarray 데이터만 적용이 되며 list 데이터의 경우 Copy=False로 설정하여도 원본 데이터는 유지됩니다.

끝~~

'python' 카테고리의 다른 글
| Python Pandas loc, iloc 비교, indexing 설명 (0) | 2022.08.23 |
|---|---|
| Python Pandas 자료구조 DataFrame 알아보기 (0) | 2022.08.17 |
| Python Pandas DataFrame.value_counts()(DataFrame 값 개수 세기) (0) | 2022.08.11 |
| Python Pandas Series.value_counts()(Series 개수 세기) (0) | 2022.08.07 |
| Python Pandas 엑셀 데이터 순서 정리(sort_values()) (0) | 2022.08.06 |



